The summer is almost gone but, looking back, it has been pretty productive from the YaST perspective. We have fixed a lot of bugs, introduced quite interesting features to the storage layer and the network module refactoring continues to progress (more or less) as planned.
So it is time for another sprint report. During the last two weeks, we have been basically busy squashing bugs and trying to get the network module as feature-complete as possible. But, after all, we have had also some time to improve our infrastructure and organize for the future.
YaST2 Network Refactoring Status
Although we have been working hard, we have not said a word about the yast2-network refactoring progress since the end of July, when we merged part of the changes into yast2-network 4.2.9 and pushed it to Tumbleweed. That version included quite a lot of internal changes related to the user interface and a few bits of the new data model, especially regarding routing and DNS handling.
However, things have changed a lot since then, so we would like you to give you an overview of the current situation. Probably, the most remarkable achievement is that the development version is able to read and write the configuration using the new data model. OK, it is not perfect and does not cover all the use cases, but we are heading in the right direction.
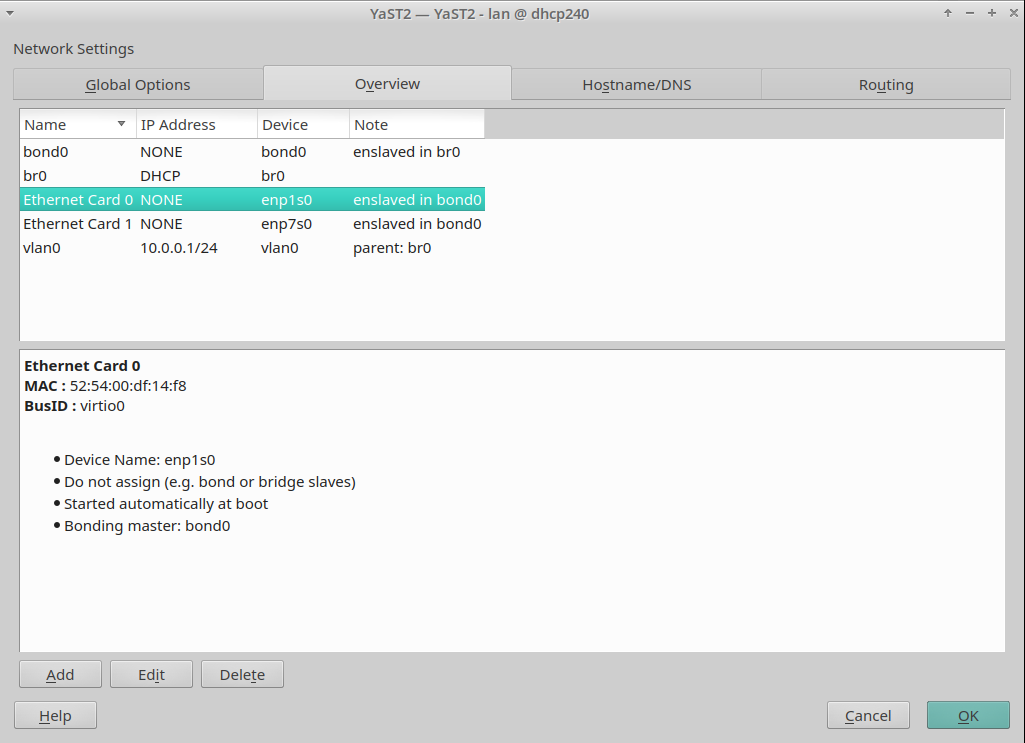
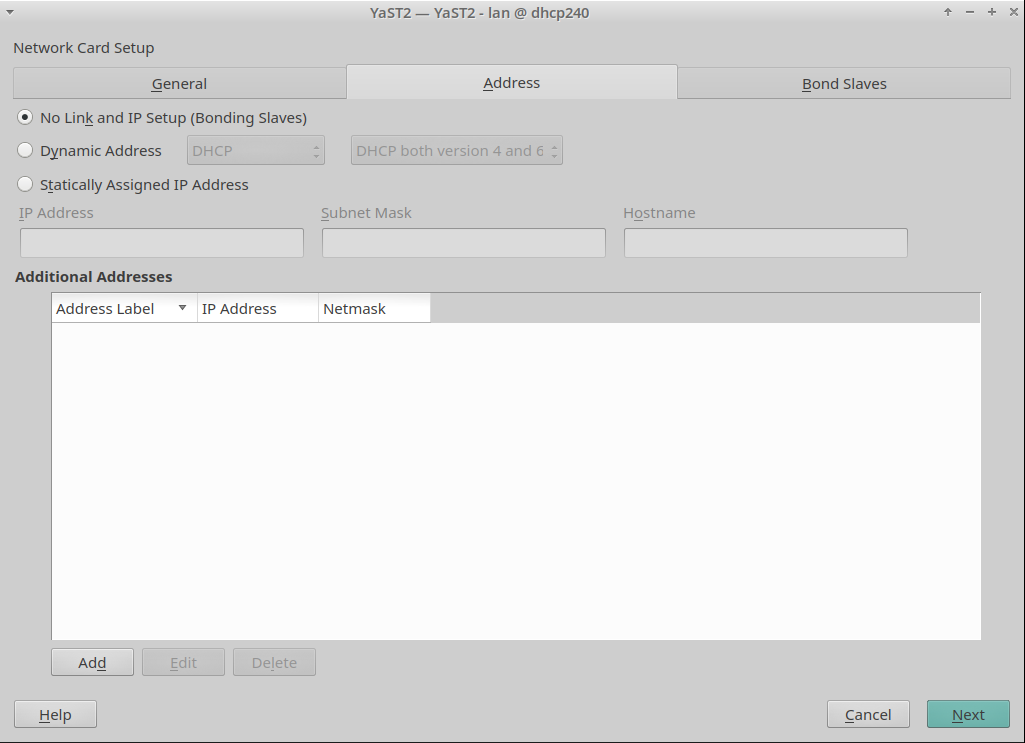
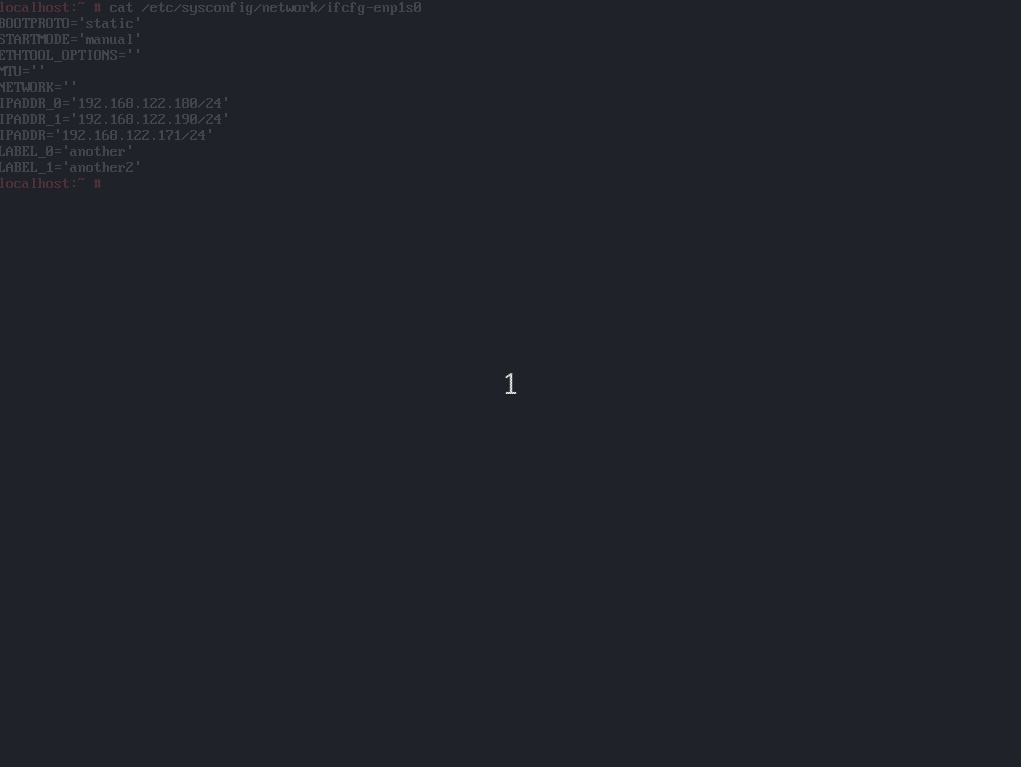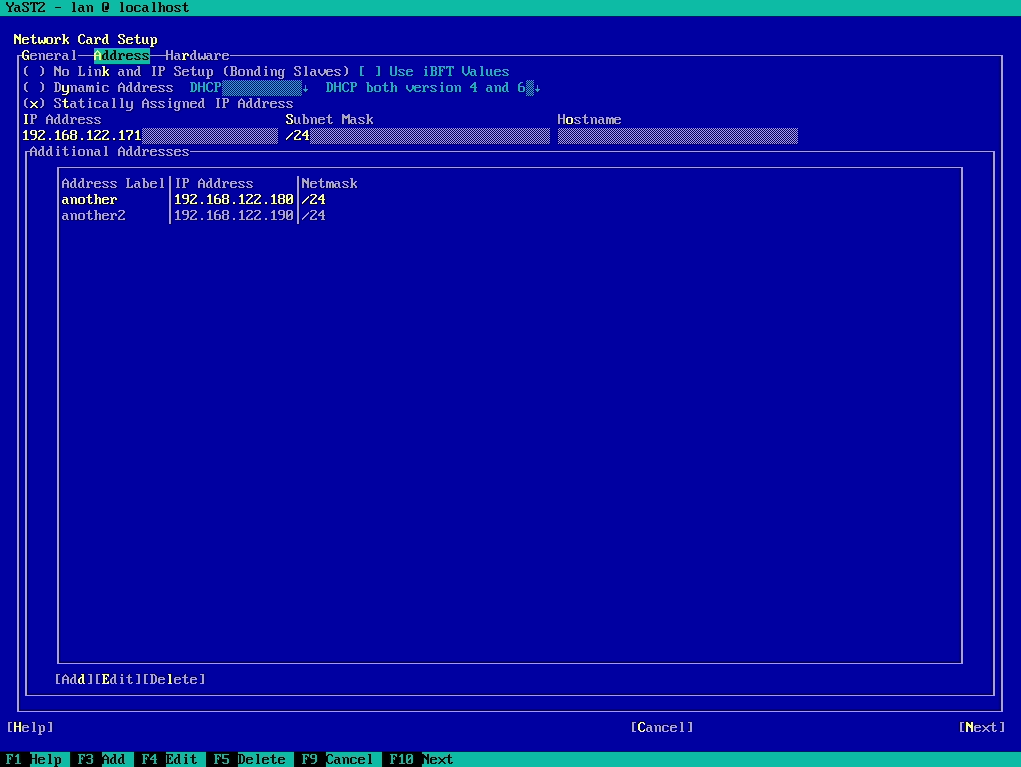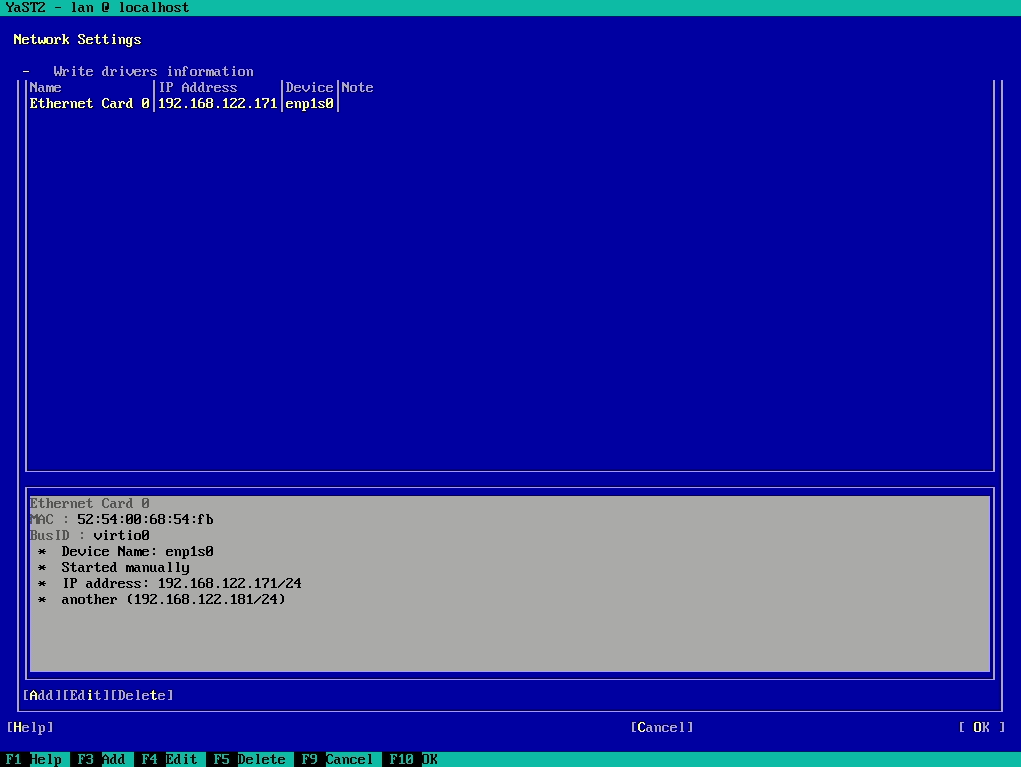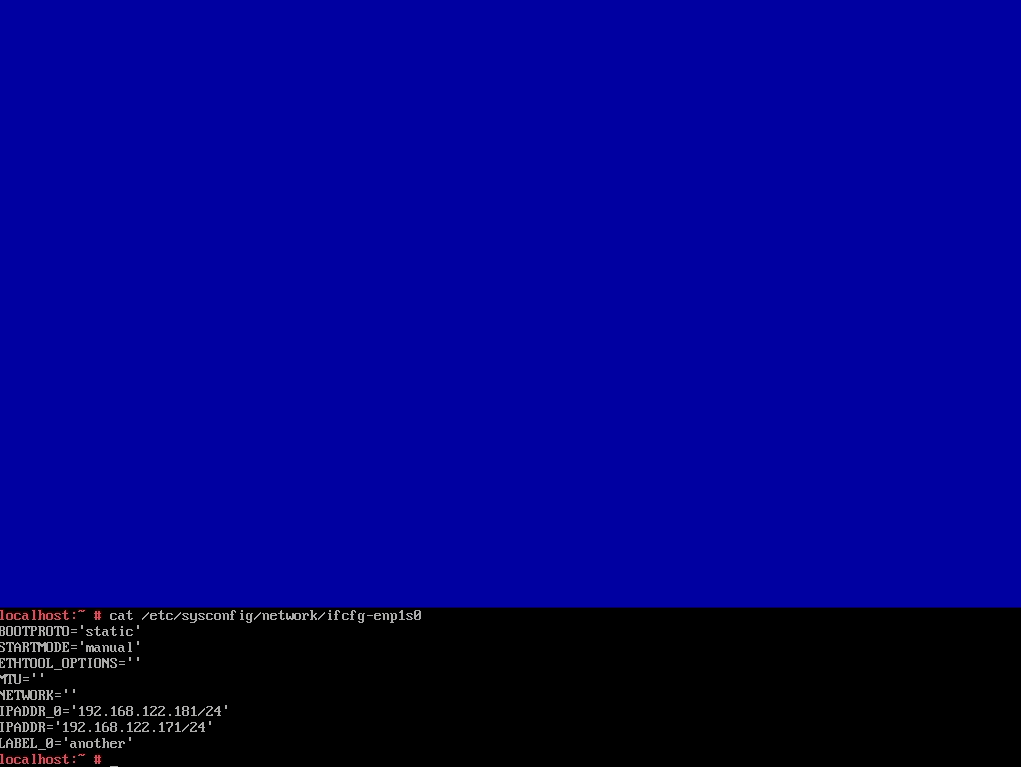
In the screencast below you can see it in action, reading and writing the configuration of an interface. The demo includes handling aliases too, which is done way better than the currently released versions.
Moreover, we had brought back support for many types of devices (VLAN, InfiniBand, qeth, TAP, TUN, etc.), improved the WiFi set-up workflow and reimplemented the support for renaming devices.
Now, during the current sprint, we are focused on taking this new implementation to a usable state so we can release the current work as soon as possible and get some feedback from you.
Finally, if you like numbers, we can give you a few. Since our last update, we have merged 34 pull requests and have increased the unit test coverage from 44% in openSUSE Leap 15.0/SUSE Linux Enterprise SP1 to around 64%. The new version is composed of 31.702 (physical) lines of code scattered through 231 files (around 137 lines per file) vs 22.542 in 70 files of the old one (more than 300 lines per file). And these numbers will get better as we continue to replace the old code 🙂
Missing Packages in Leap
It turned out that some YaST packages were not updated in Leap 15.1. The problem is that, normally, the YaST packages are submitted to the SLE15 product and they are automatically mirrored to the Leap 15 distribution via the build service bots. So we do not need to specially handle the package updates for Leap.
However, there are few packages which are not included in the SUSE Linux Enteprise product line, but are included in openSUSE Leap. Obviously these packages cannot be updated automatically from SUSE Linux Enterprise because they are not present there. In this case Leap contained the old package versions from the initial 15.0 release.
In order to fix this issue, we manually submitted the latest packages to the Leap 15.2 distribution. To avoid this problem in the future we asked the Leap maintainers to add the Leap specific packages to a check list so they are verified before the next release. Of course, if you see any outdated YaST package in Leap you can still open a bug report. 😉
Just for reference, the affected packages are: yast2-alternatives, yast2-slp-server, yast2-docker and skelcd-control-openSUSE (the content is only present on the installation medium, it’s not released as an RPM).
Let’s use all disks!
As you may remember, three sprints ago we added some extra configuration options to make the storage guided proposal able to deal with the SUSE Manager approach. We even wrote a dedicated blog post about it!
Despite offering the new options in the Guided Setup, we tried to keep the default initial behavior of the installer consistent with other (open)SUSE products. So the installer initially tried to install the whole system in a single disk, unless that was impossible or it was told by the user to expand on several disks.
But the SUSE Manager folks found that to be contrary to the new ideas introduced in their Guided Setup. According to their feedback, in this case remaining consistent with other (open)SUSE product was not reducing the confusion, but rather increasing it. SUSE Manager should try from the very beginning to expand the product as much as possible among all available disks.
For that reason, during this sprint we introduced the first improvement (a.k.a. another configuration option), so now it is possible to tell whether the initial proposal should try to use multiple disks as first try.
Bootloader and Small MBR Gaps
We received a bug report because a system was not able to boot after installation. In this case, the user decided to use Btrfs and placed the root file system in a logical partition. In theory, this scenario should work but, unfortunately, the MBR gap was too small to embed the Grub2 bootloader code.
At first sight, this problem could be solved by asking YaST to install the bootloader into the logical partition and the generic boot code in the MBR. But this will only work if you set the logical partition as the active one. Sadly, some BIOSes could insist on having a primary partition as the active one.
But don’t worry, we have good news. Grub2 maintainers took care of this problem. In case the MBR gap is too small, Grub2 will automatically fall-back to the Btrfs partition. That’s all. And what does it mean for YaST? Well, thanks to this fix, YaST will simply work out of the box and your system will be bootable again. But not so fast! You still have to wait a little bit more to have these Grub2 improvements available in a Tumbleweed installer.
AutoYaST supports defining an specific NTP configuration to be applied during the installation and it relies in Augeas to read/write the ntp.conf file. But it seems that Augeas has some problems when it tries to write comments with empty lines, as you can see in bug 1142026. The solution was to adapt YaST to filter out empty comment lines before saving the configuration file, working around the Augeas problem.
Error Resizing Some Partitions
Typically, an MS-DOS partition table reserves its first MiB for the MBR gap, so the partitions normally start after that point. But it is possible, especially in partitions for old Windows systems, that it starts before that first MiB. In that case, if we try to resize that partition (e.g., by using the Expert Partitioner), YaST crashes due to an error when calculating the resize information. Fortunately, this problem is gone now, and you will be able to resize this kind of partitions as well.
Side Effects of Keyboard Layouts Unification
During the sprint 81, the openSUSE and SUSE Linux Enterprise console keyboard layouts were unified after some minor changes. One of those changes was to stop using the, in appearance, useless keymaps symlinks for Arabic and Cambodian. But they were there for a reason: are being used by YaST to correctly adapt the keyboard in the X11 environment. Just visit the pull request if you prefer to scare yourself want to dive in more technical details.
Fortunately for the users of those keyboards, we realized about this problem before the upcoming SLE-15-SP2 was released 🙂 And, it’s fixed.
House Keeping Tasks
As part of our development duties for this sprint, we invested quite some time in reviewing and updating our continuous integration (CI) set up. Apart from using Travis CI for pull requests, we rely on Jenkins to run the tests and submit the code to the appropriate projects in the Open Build Service instances.
Then, when the development of a new version starts or when the product is about to be released, we need to adjust the configuration. Just in case you are wondering, we do not do this work by hand anymore and we use Salt and Jenkins Job Builder to handle this configuration.
Closing Thoughts
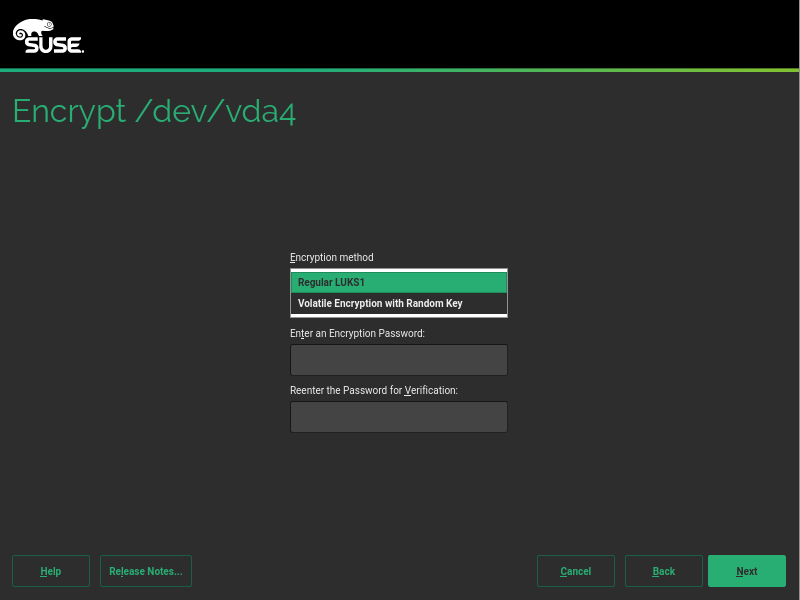
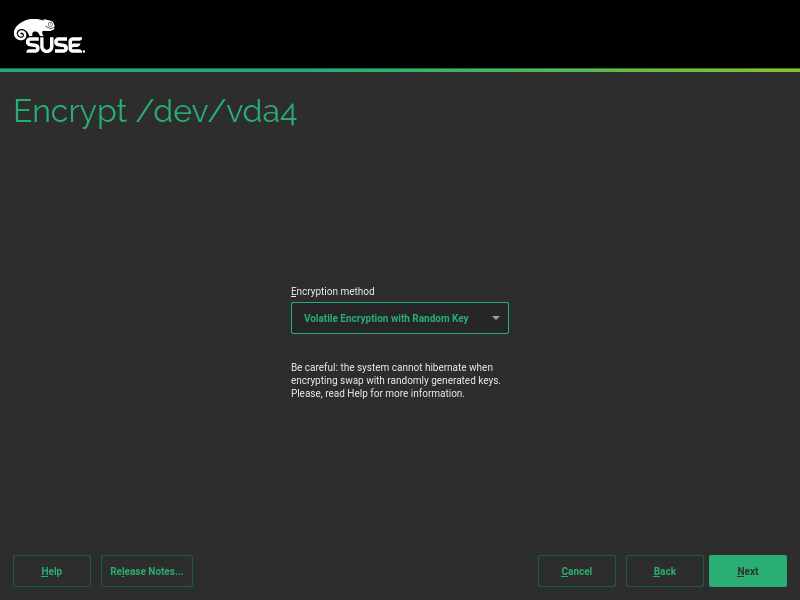
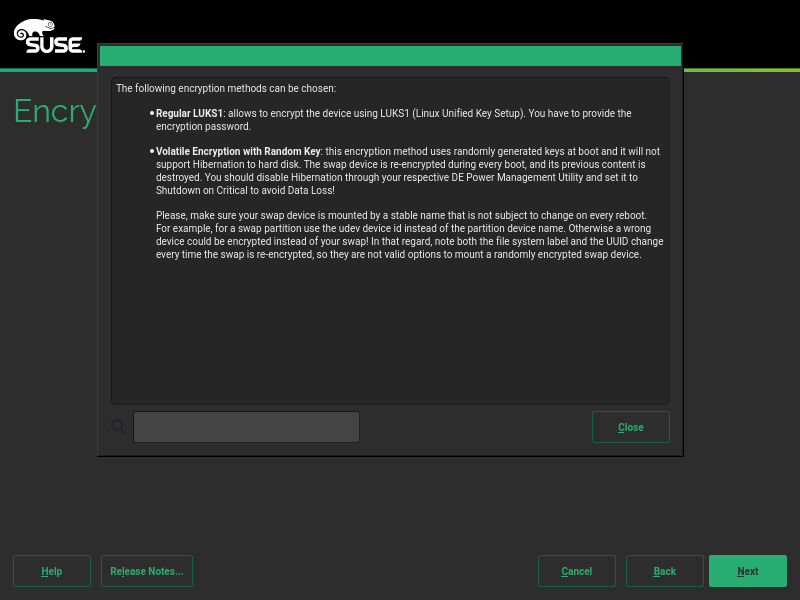
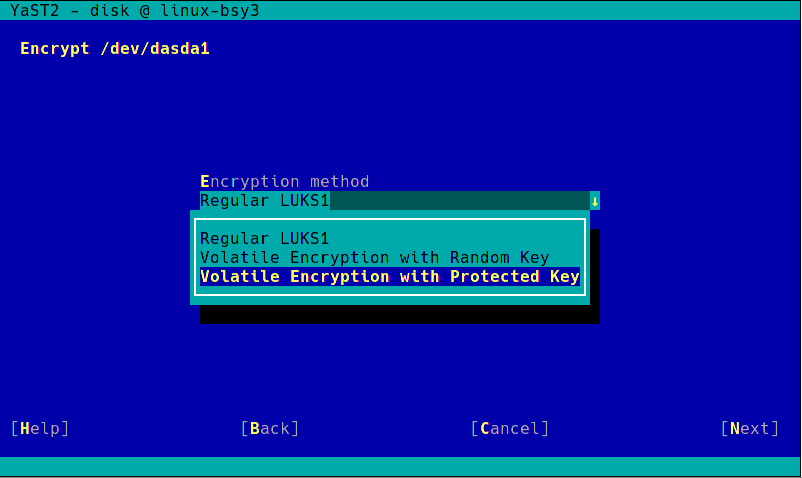
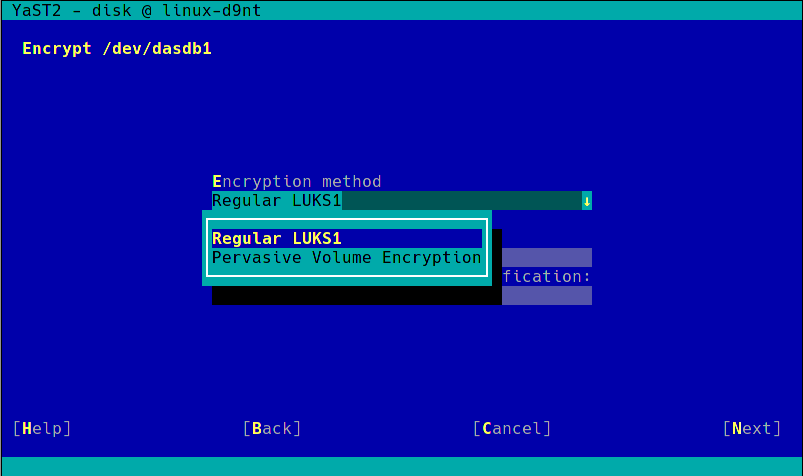
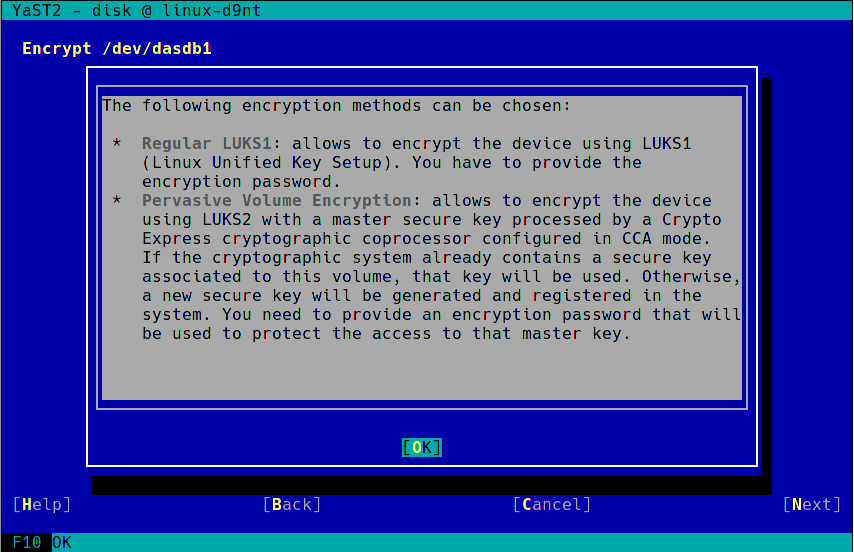
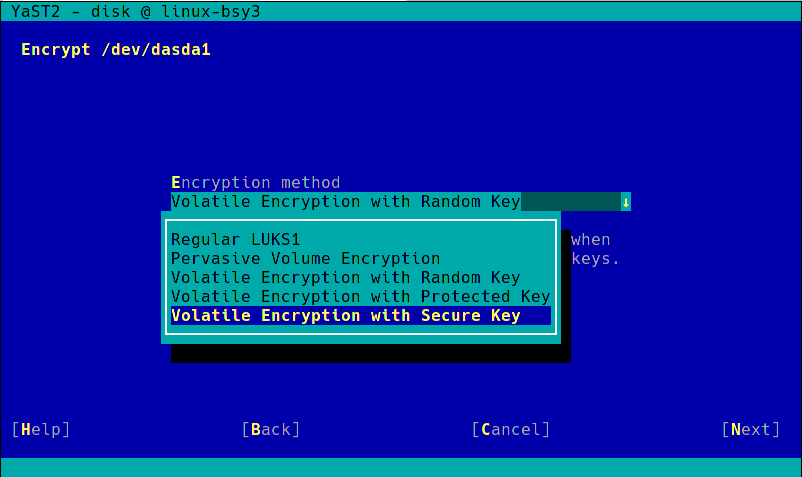
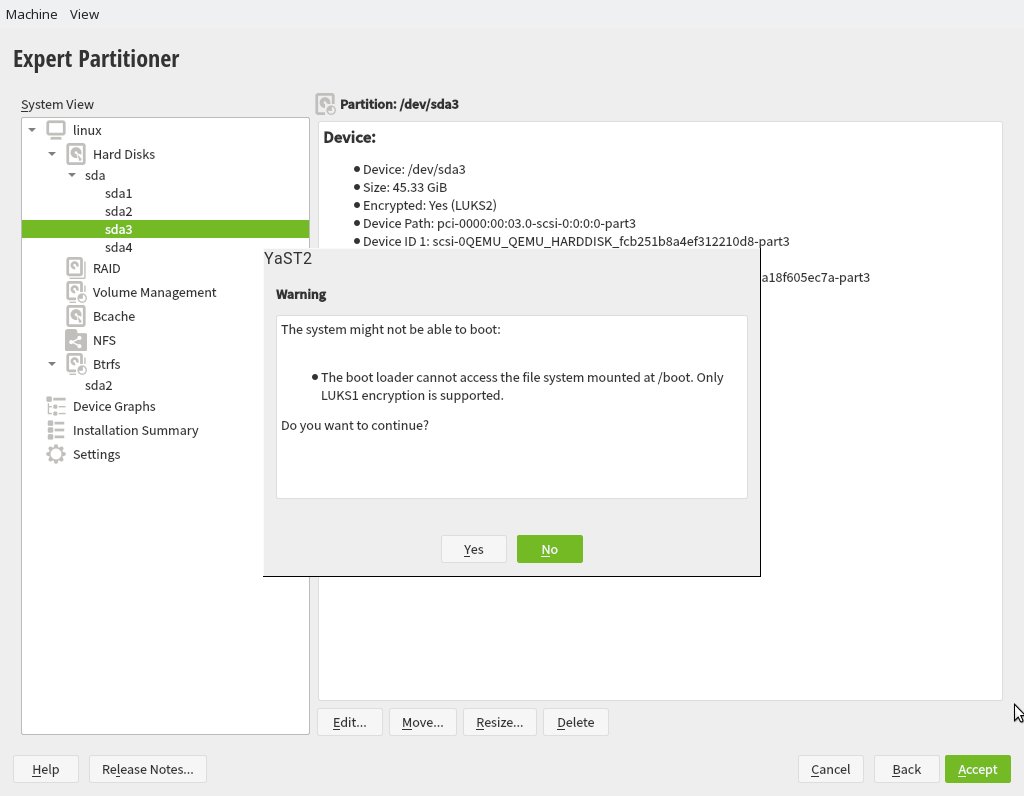
During the next sprint (actually, the current one) we are working in three different areas, apart from squashing bugs: improving encryption support in the storage layer, adding some features to the installer (repo-less installer, support for reading product licenses from a tarball, etc.) and, of course, refactoring the network code. Obviously, we will give you all sort of details in our next sprint report.