openSUSE Conference 2017 is coming! And as we flight there (literally, one third of the YaST team is in a plane right now typing this), we wanted to inform our beloved readers on what we did in the previous three weeks.
So here is our report, brought to you by airmail!
Bugfixes, bugfixes everywhere
Leaving openSUSE Tumbleweed aside, The YaST team is currently working to deliver SLE12-SP3, openSUSE Leap 42.3, SLE15, openSUSE Leap 15, SUSE CaaSP 1.0 and Kubic (more about Kubic later). Three of them are already in beta phase, which means they are being extensively tested by several parties and in many scenarios, hardware platforms and possible configurations. That amount of manual testing always result in several bug being discovered, no matter how much we try to have some automated tests for the most common cases.
Many of the bugs our testers are finding are related to internationalization and localization, mainly texts in the UI that are always displayed in English, despite the system been configured (or being installed) in a different language.
But, of course, other kind of bugs are also being found. For example, our hardware detection component (hwinfo) was not able to deal with some new machines, making the installation experience everything but pleasant.
As a result, a significant amount of the YaST team manpower during this sprint was targeted to squash those annoying bugs. Which doesn’t mean we didn’t have time for some interesting new features and improvements.
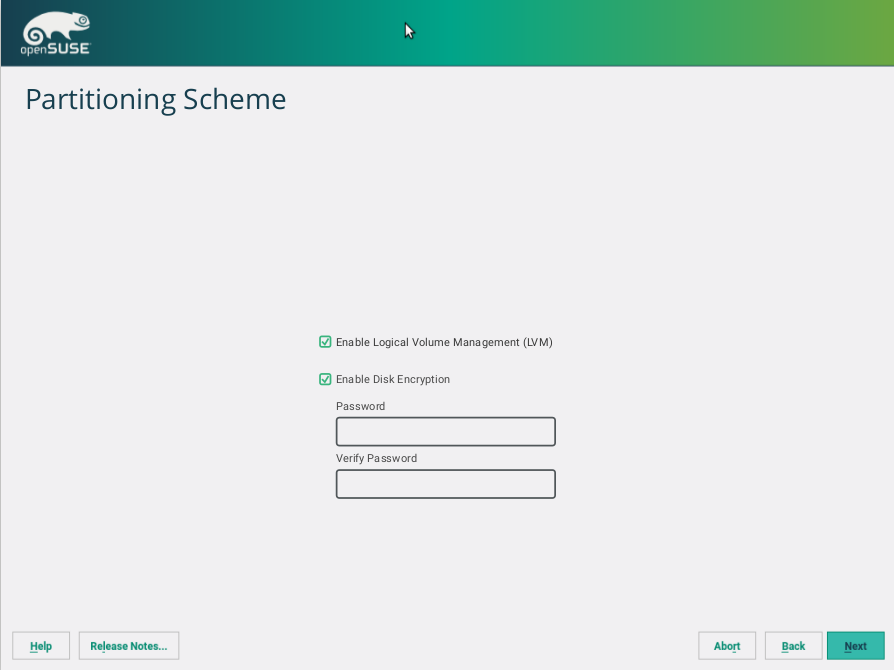
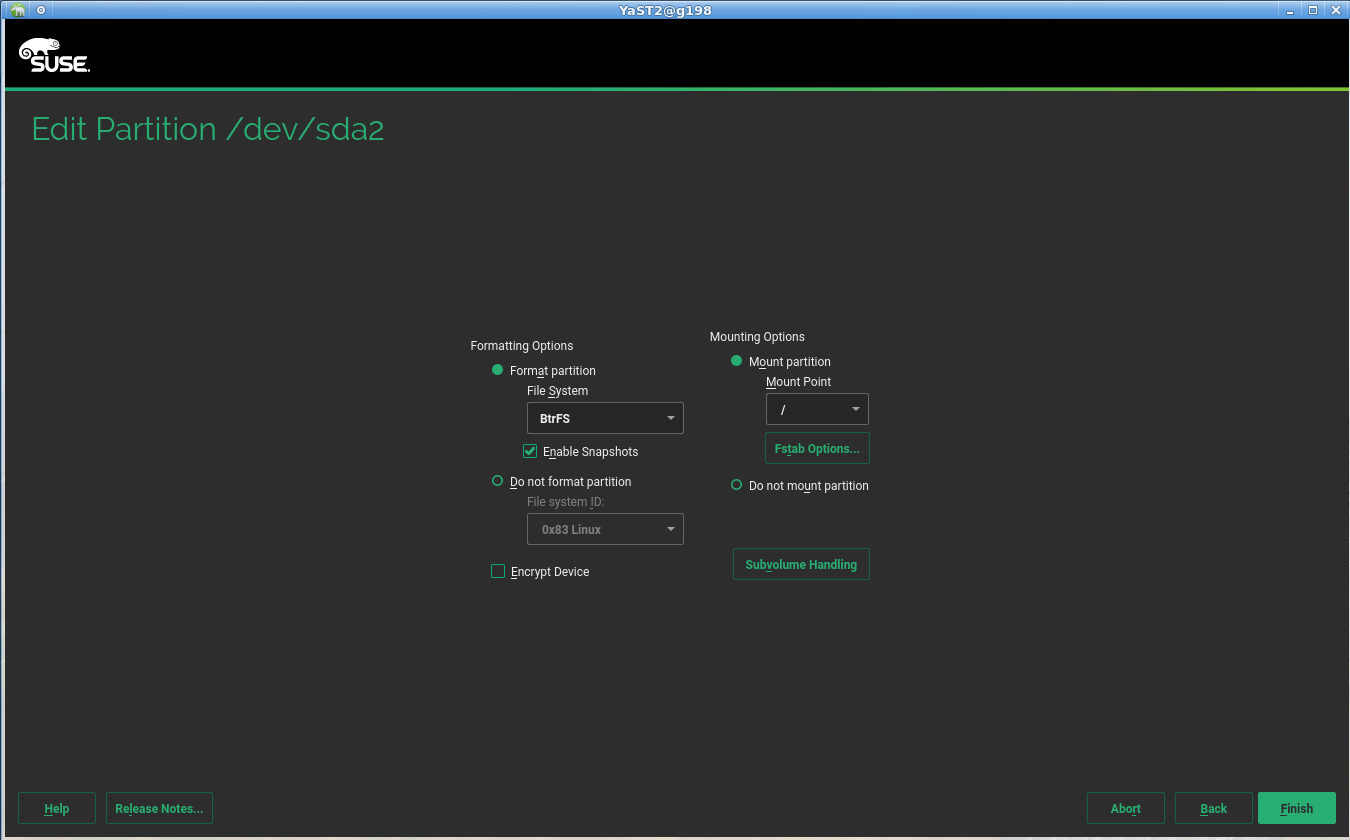
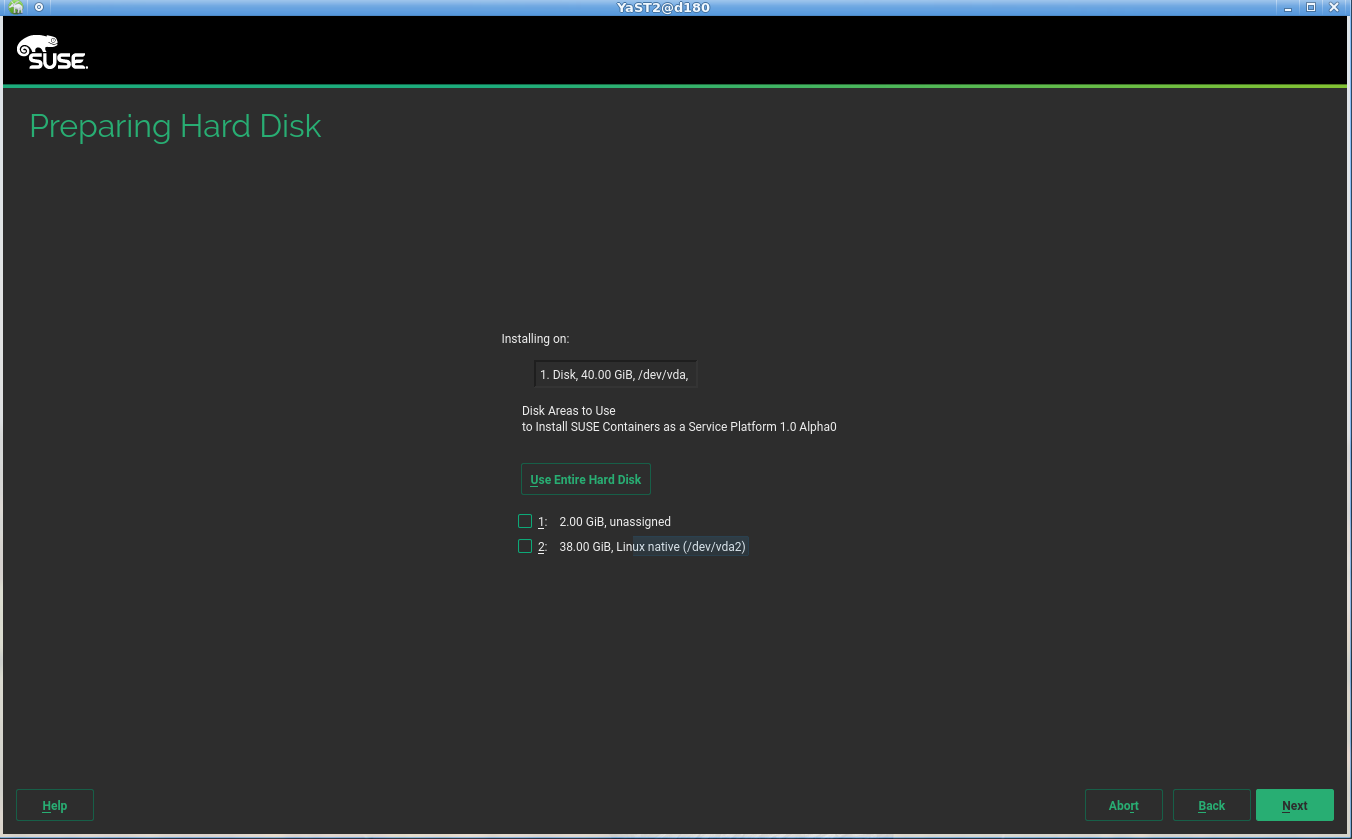
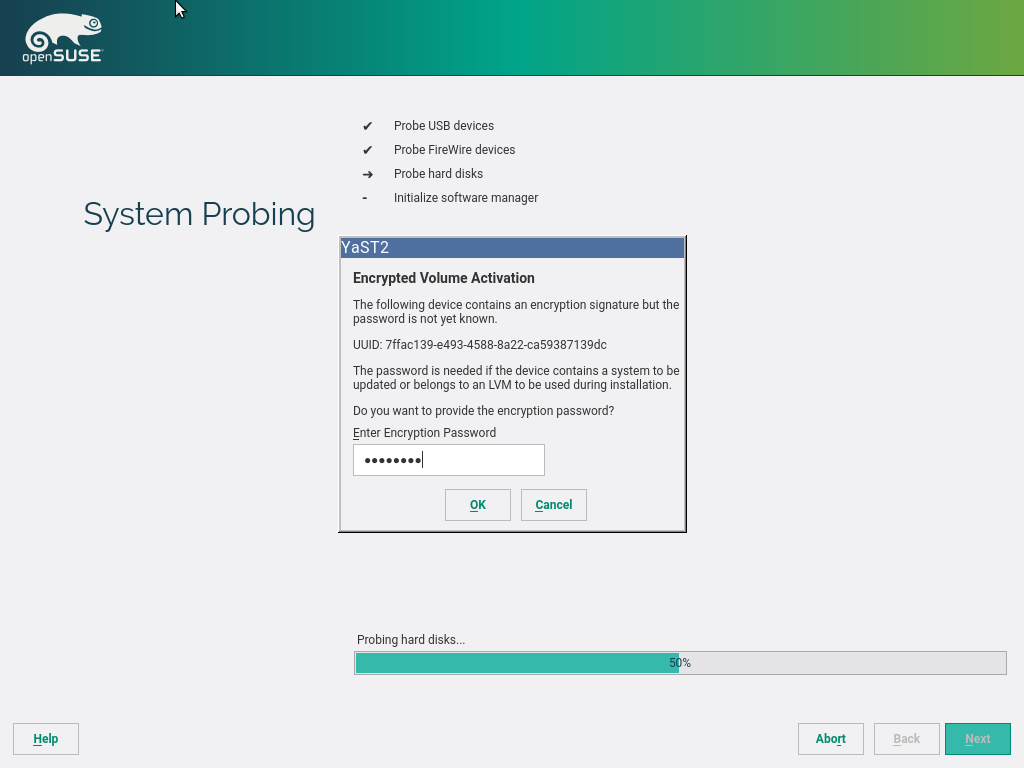
Storage reimplementation: unlock encrypted devices
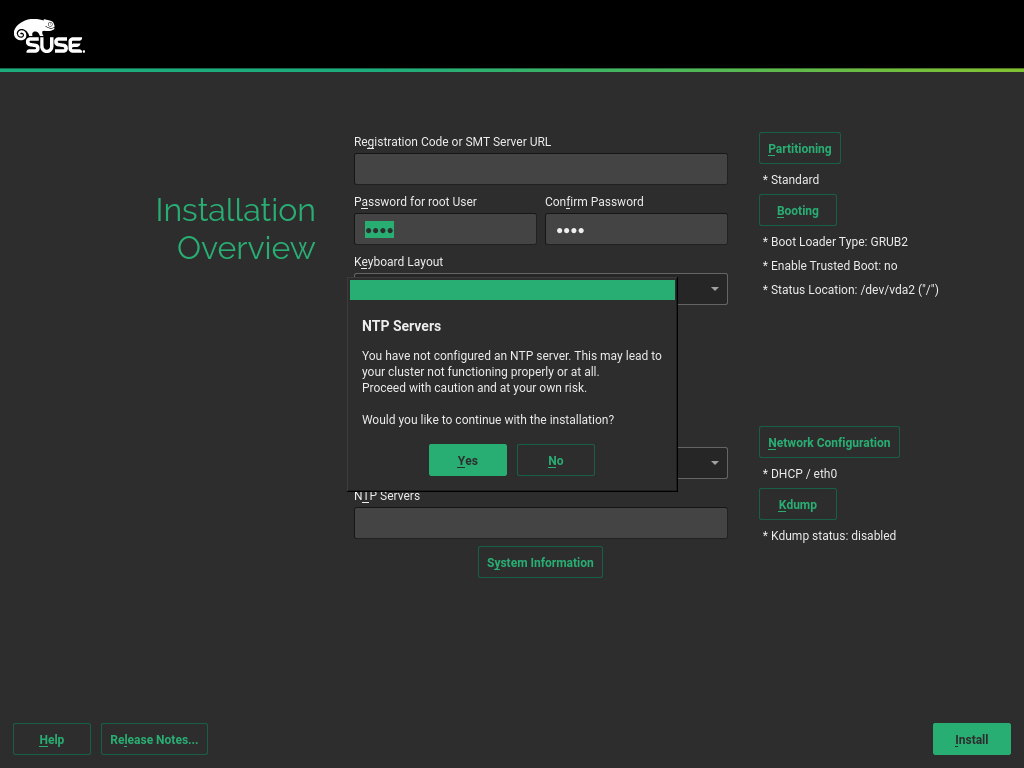
Once again, our new storage system comes with news. Now it’s able to detect and unlock preexisting encrypted devices during the hard disks probing step, raising you a new pop-pup dialog to ask for the corresponding device password. After unlocking the devices, all your installed systems will be accessible for upgrade and, moreover, the LVM volumes allocated over encrypted devices will be activated.
The new storage stack is expected to debut in SLE15 (and, thus, openSUSE Leap 15), but the functionality can already be tested, for both the installation and upgrade processes, with the StorageNG test ISOs.
The storage reimplementation & AutoYaST – a love story
But the happiest news coming from the new storage stack during this sprint is it’s marriage with AutoYaST. The new automatic partitioning proposal (that is, the “Guided Setup”) is now integrated with AutoYaST.
Thanks to the new software architecture, AutoYaST users will be able to override every single partitioning setting from the control file.
<profile xmlns="http://www.suse.com/1.0/yast2ns" xmlns:config="http://www.suse.com/1.0/configns">
<general>
<storage>
<!-- Override settings from control file -->
<try_separate_home config:type="boolean">false</try_separate_home>
<proposal_lvm config:type="boolean">true</proposal_lvm>
</storage>
</general>
</profile>
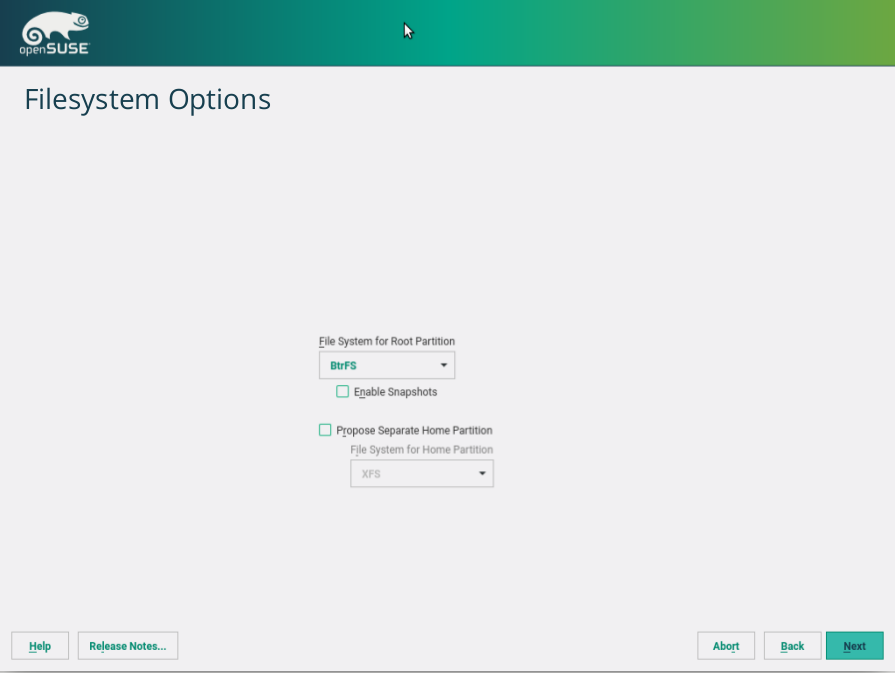
So you can easily switch on/off LVM, use a separate partition for /home, enable/disable snapshots, enable/disable Windows resizing, etc. All that, still relying on the automated storage proposal to iron the details up. Something that is not possible with the current version of AutoYaST without being forced to define explicitly every partition and LVM volume.
But the simplest way to use the new libstorage proposal is to not define any setting at all in the AutoYaST configuration file. In that case, the partitioning proposal code will do the complete job, installing a new system with the default options.
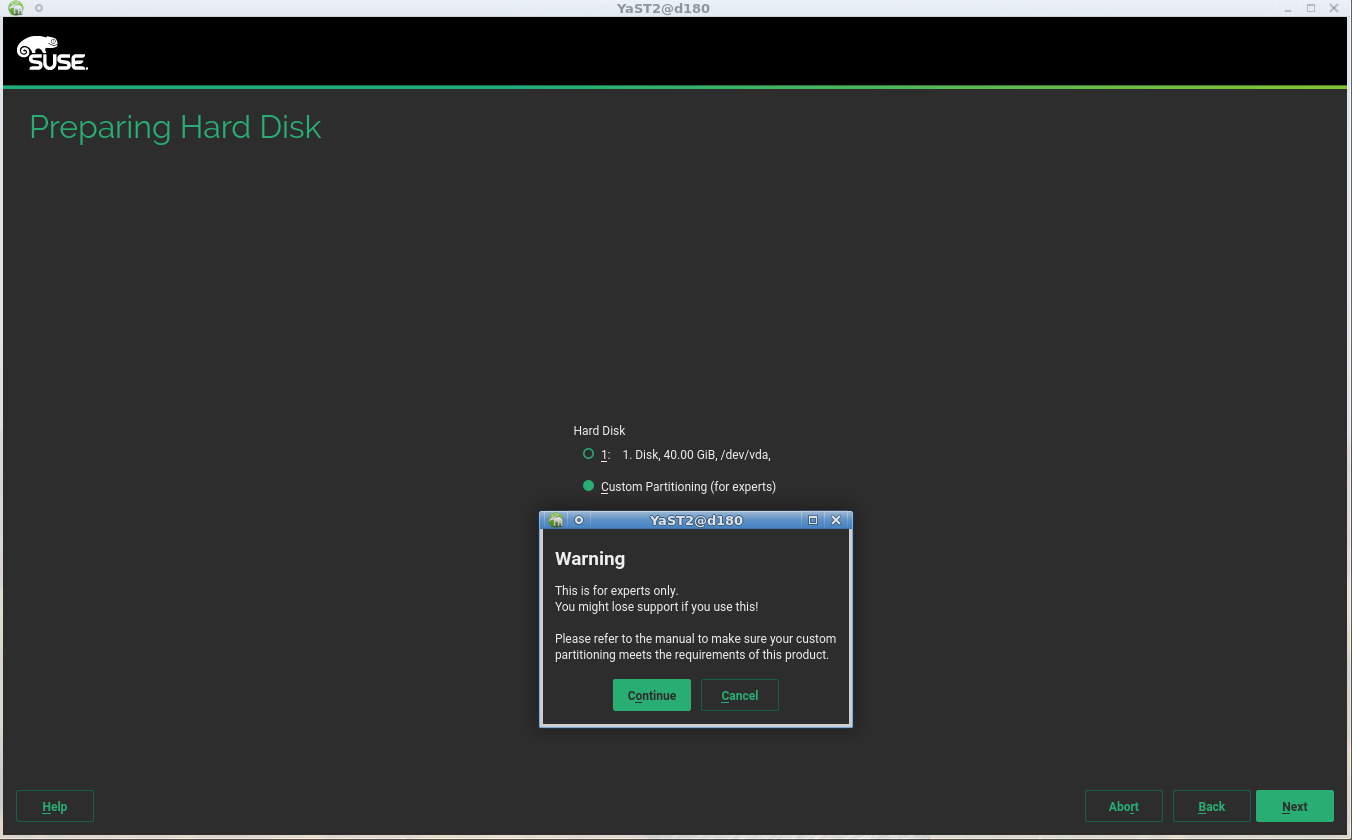
Of course, before integrating the new storage stack into the upcoming SLE15, the AutoYaST support have to go one step further. Apart from using and configuring the proposal, it must be possible to define a completely custom setup including partitions, LVM volumes, software RAID devices and so on through the corresponding <partitioning> section of the AutoYaST profile. So we used this sprint to sketch a plan to make that possible in the following months, analyzing all the scenarios and configurations supported by AutoYaST and looking for the best way to support them using the existing yast2-storage-ng infrastructure. The outcome of that effort is this detailed document and a list of tasks (PBIs in Scrum jargon) for the upcoming sprints. So be prepared for more news in this regard.
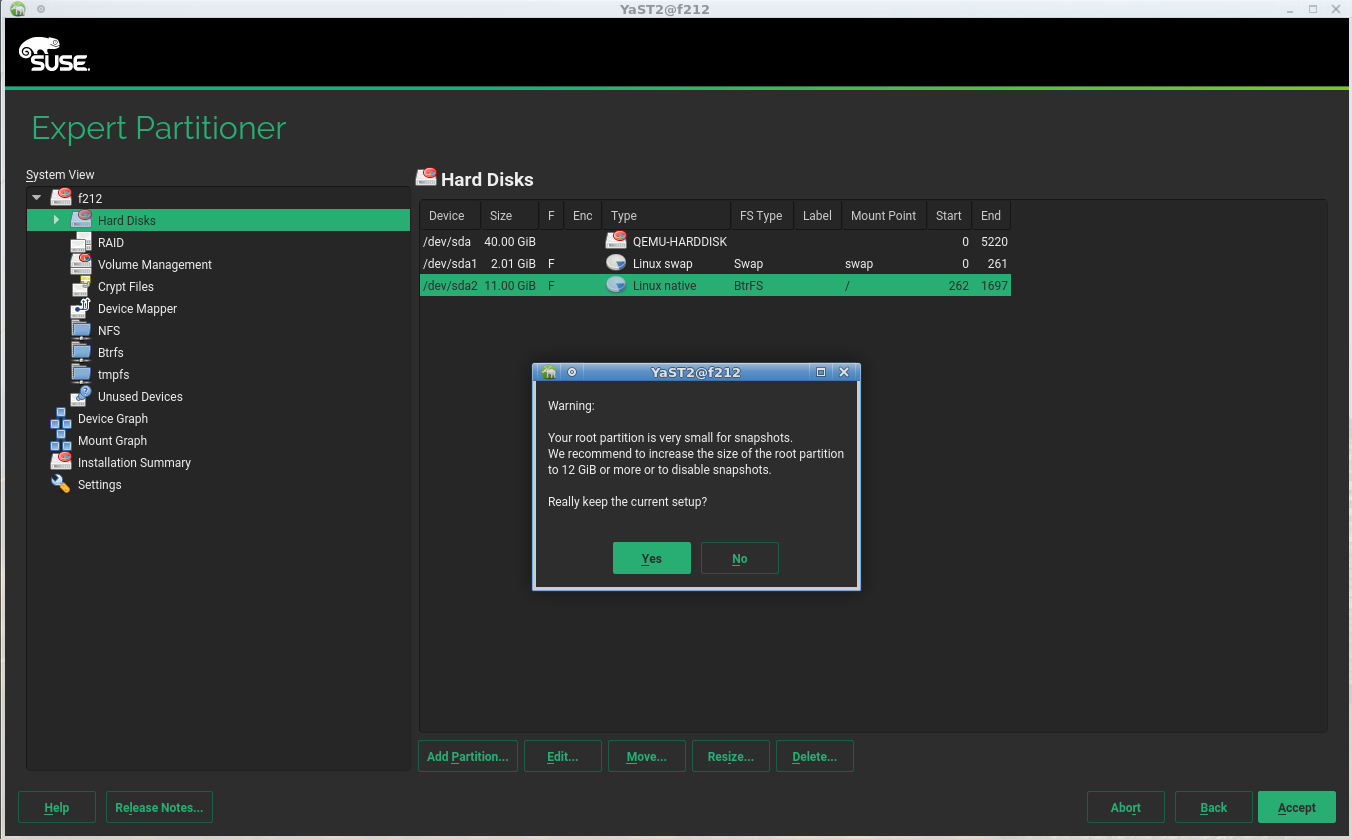
Automatic Cleanup of Snapshots created by Rollback
So far the user had to ensure that snapshots created by rollbacks got deleted to avoid filling up the storage. This process has now been automated. During a rollback, Snapper now sets the cleanup algorithm to “number” for the snapshot corresponding to the previous default subvolume and for the backup snapshot of the previous default subvolume. This enhanced behavior will be available in SLE12-SP3 and openSUSE Leap 42.3. For more information take a look at the more detailed post in the Snapper blog.
Helping to bring the CaaSP fun to openSUSE
For several sprints already we have been presenting features targeted to SUSE CaaSP, the Kubernets-powered solution for managing containers. Many of those features and custom configurations live in a package called yast2-caasp, originally targeted to this great upcoming product built on top of the SLE12-SP2 codebase.
But now the package is also available for Tumbleweed-based systems by request of the Kubic project. Kubic will be the openSUSE alter ego of SUSE CaaSP, that is, a Container as a Service Platform based on openSUSE and Kubernetes. As with any other YaST component, the exact same source code will shared by the SUSE product and its openSUSE brother.
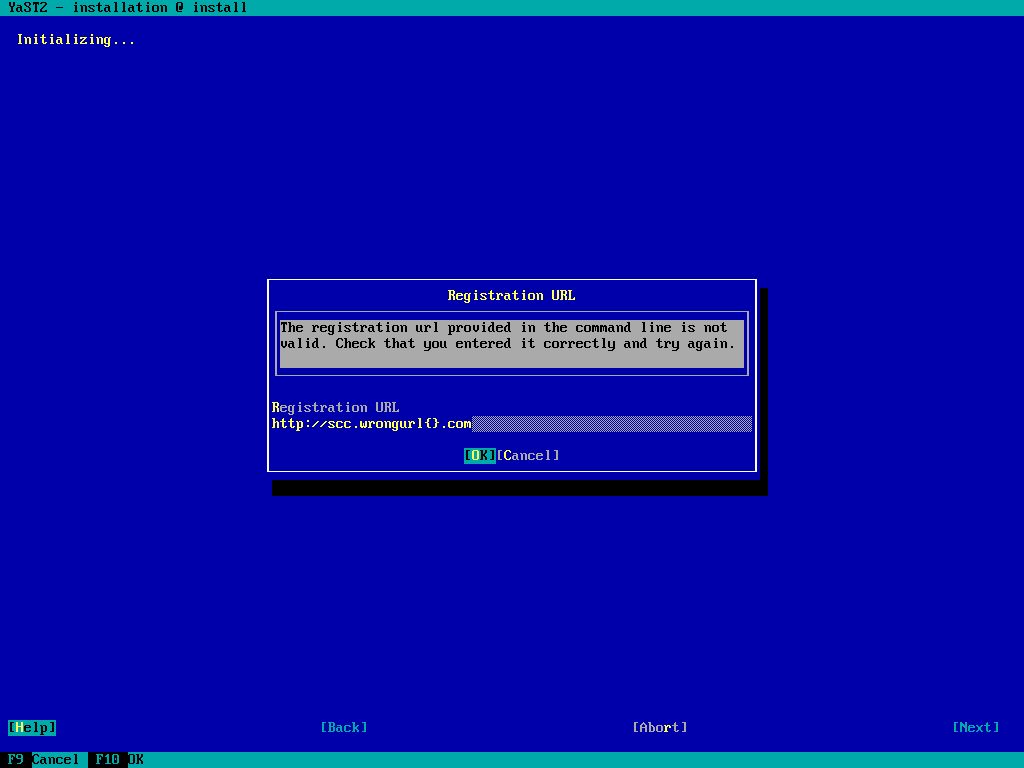
Improved UX when an invalid registration URL is provided
Humans make mistakes, but when the mistakes are made entering some option in
the installation command line, it usually means that a reboot of the machine is be needed to fix them.
That was the case for the registration URL (regurl) option. In the provided address was malformed the installation just stopped. During this sprint we have added an early check of that URL which allows the user to reenter it and continue with the installation. Something that obviously improves the user experience.
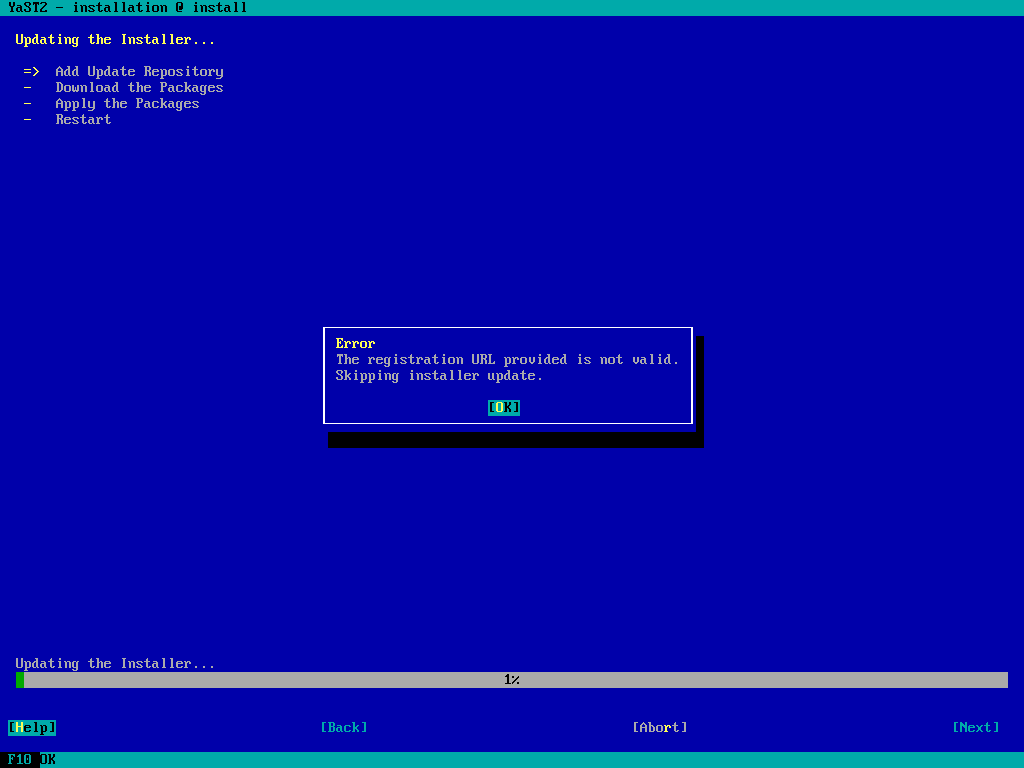
In case of an autoinstallation (AutoYaST), the error is reported and the steps to get installer updates and to register the system are skipped.
There is still room for more improvements, allowing the user to also modify the URL in other scenarios. For example, for an URL with a valid format but that points to an unreachable server. But in those cases is not so straightforward to identify the culprit of the problem. It would make no sense to annoy the user with a recurring pop-up to change the registration URL if the root of the issue is not the URL but a incorrect network configuration.
Translations and Interpolations
As mentioned at the begining of this post, we recently got quite some bug reports about missing translations. Although some of them were really caused by bugs in the YaST code, others were a consequence of a buggy Ruby rxgettext script which collects the translatable strings from the Ruby source code. The bug is known by the Ruby-GetText developers, but it’s unclear when (or whether) it will be fixed.
The problem is that the tool cannot collect the translatable strings from interpolations. For example it cannot find the “foo” string from this string literal: "#{_("foo")}". As a result, that string is missing in the resulting POT file and cannot be translated by the SUSE or openSUSE localization teams.
As a workaround, we fixed the YaST code to not use the translations inside interpolations. We also documented the possible problems when mixing translations a interpolations and their solution.
And talking about new developer oriented documentation…
Security Tips for YaST Developers
YaST runs with the administrator privileges (root) and therefore we have to be aware of the possible security issues in the code. During this sprint we published a document with a short summary of security tips for YaST developers.
If you are programming an YaST module you should definitely read it, but it might be interesting also for other programmers as many mentioned issues are generic, not tight only to YaST.
The document is available online here.
See you at the conference
That’s all for this sprint report. We have many more things in the oven, be we didn’t manage to finish them during the sprint, so they will have to wait for the next report. Meanwhile we hope to see many of you at the openSUSE Conference 2017. There will be a whole workshop about modern YaST development, a summary with the more relevant news in the last year of YaST development, talks about the new superb yast2-configuration-management module, about our continuous delivery infrastructure and about how we use Docker to deliver YaST… And, of course, also many other interesting content like the awesome presentation from Thorsten Kukuk about the brand new openSUSE Kubic we mentioned earlier. And even more important, a lot of fun!

For those of you that cannot attend to the conference, see you again in this little corner of the internet in three weeks!